ReWatch-R1: Boosting Complex Video Reasoning in Large Vision-Language Models through Agentic Data Synthesis
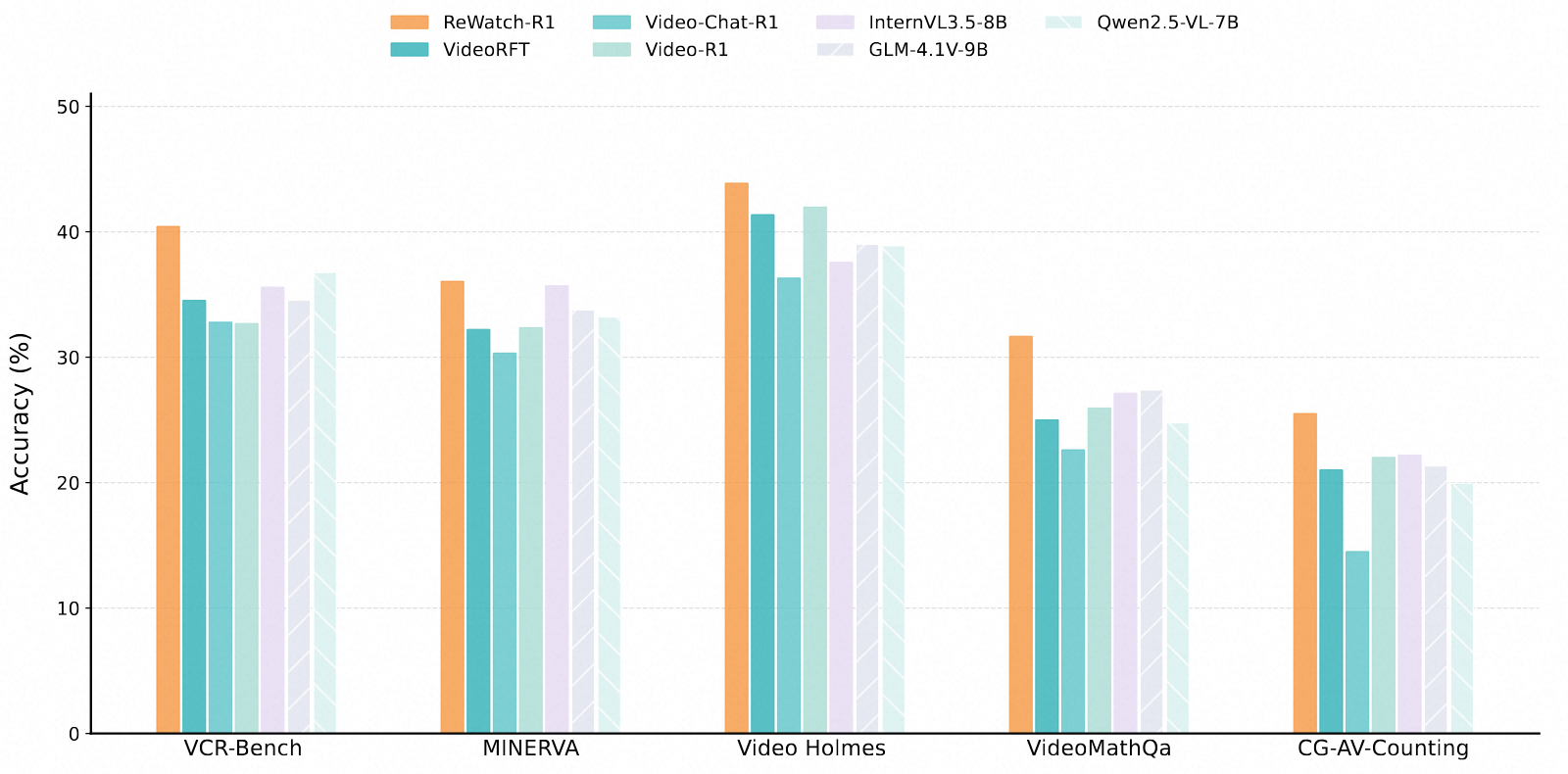
Performance comparison of our ReWatch-R1 with previous state-of-the-art LVLMs on five video reasoning benchmarks. Except for Qwen2.5-VL-7B, all other models use thinking mode. All models were evaluated at 192 frames.
Abstract
While Reinforcement Learning with Verifiable Reward (RLVR) significantly advances image reasoning in Large Vision-Language Models (LVLMs), its application to complex video reasoning remains underdeveloped. This gap stems primarily from a critical data bottleneck: existing datasets lack the challenging, multi-hop questions and high-quality, video-grounded Chain-of-Thought (CoT) data necessary to effectively bootstrap RLVR. To address this, we introduce ReWatch, a large-scale dataset built to foster advanced video reasoning. We propose a novel multi-stage synthesis pipeline to synthesize its three components: ReWatch-Caption, ReWatch-QA, and ReWatch-CoT. A core innovation is our Multi-Agent ReAct framework for CoT synthesis, which simulates a human-like "re-watching" process to generate video-grounded reasoning traces by explicitly modeling information retrieval and verification. Building on this dataset, we develop ReWatch-R1 by post-training a strong baseline LVLM with Supervised Fine-Tuning (SFT) and our RLVR framework. This framework incorporates a novel Observation & Reasoning (O&R) reward mechanism that evaluates both the final answer's correctness and the reasoning's alignment with video content, directly penalizing hallucination. Our experiments show that ReWatch-R1 achieves state-of-the-art average performance on five challenging video reasoning benchmarks.
ReWatch Dataset
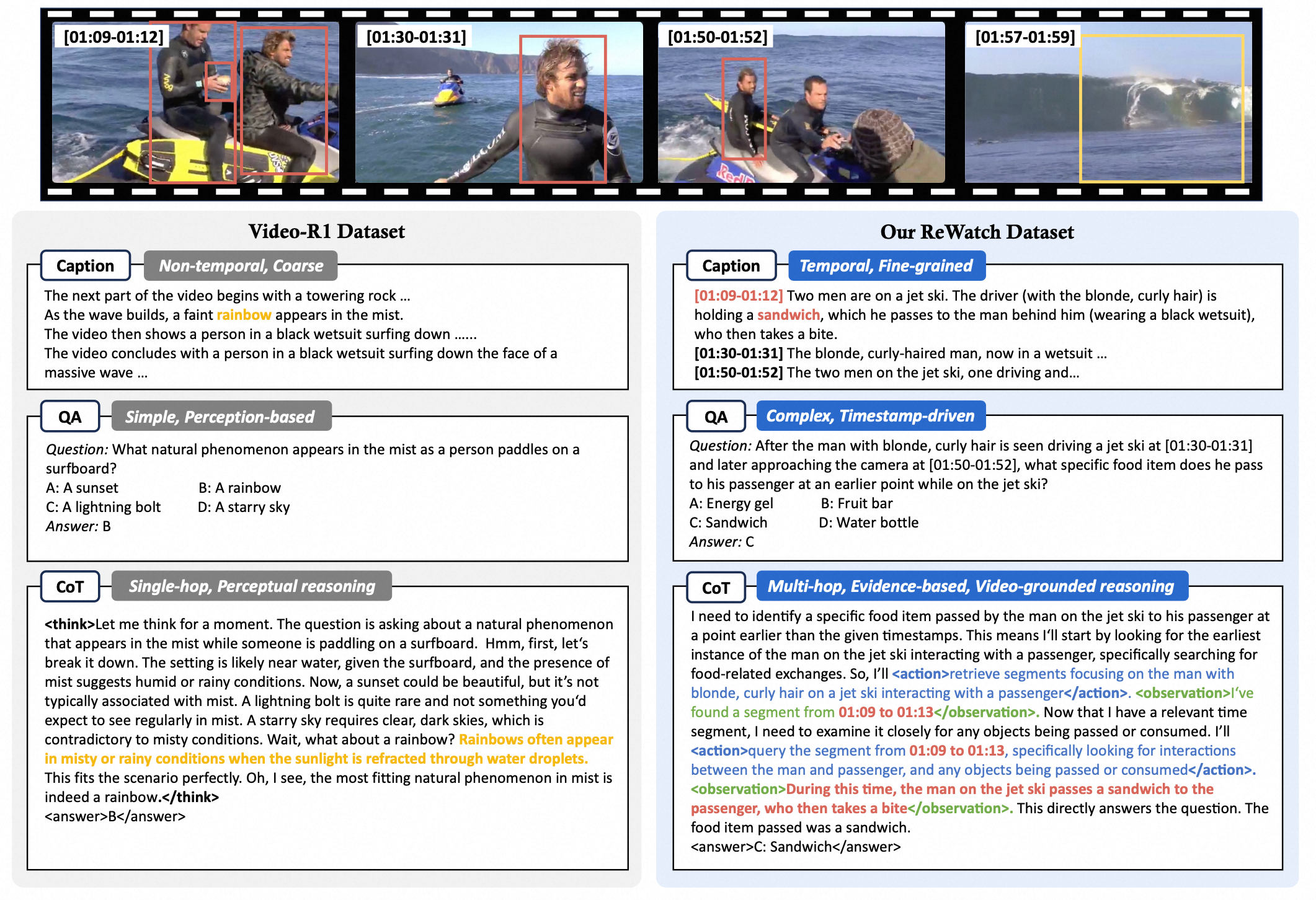
A comparative of ReWatch dataset and Video-R1 dataset on the same source video.
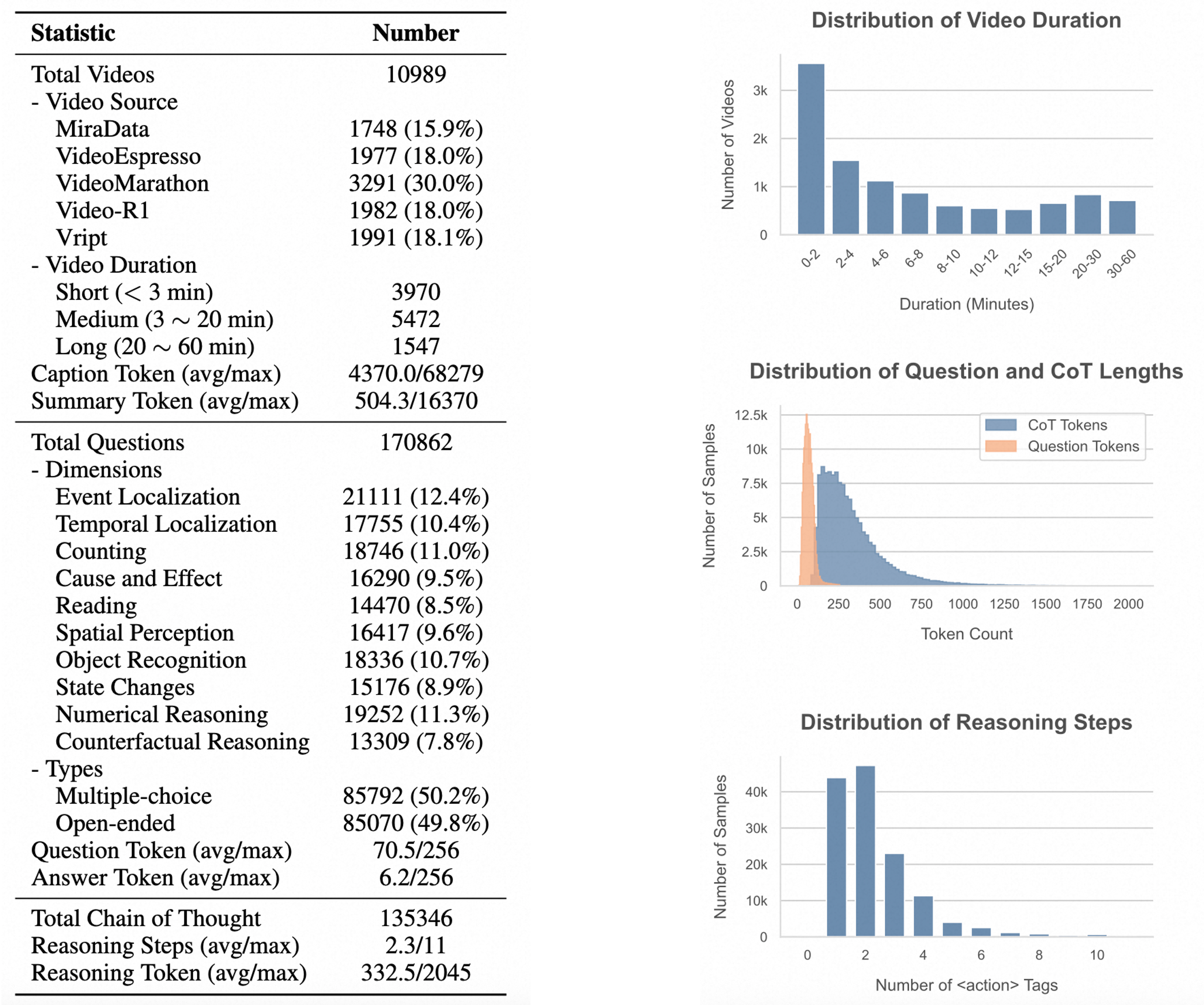
Statistics of our ReWatch dataset.
Data Construction Pipeline
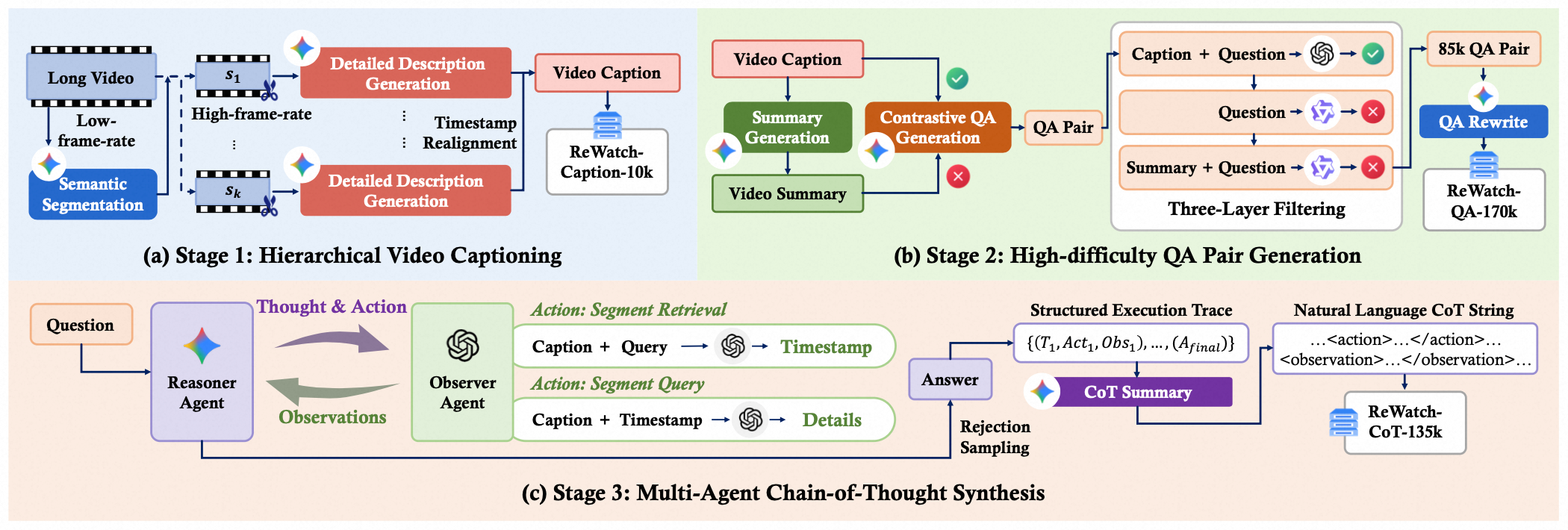
(a) Caption Construction. Long videos are semantically segmented to produce detailed, temporally-aware captions. (b) QA Pair Generation. A contrastive method using detailed and summary captions generates complex questions, which are then purified by a three-layer filtering mechanism. (c) CoT Synthesis. A ReAct framework with a Reasoner Agent and an Observer Agent simulates a "re-watching" process by performing targeted queries on the video caption to generate video-grounded reasoning traces.
Post-Training Framework
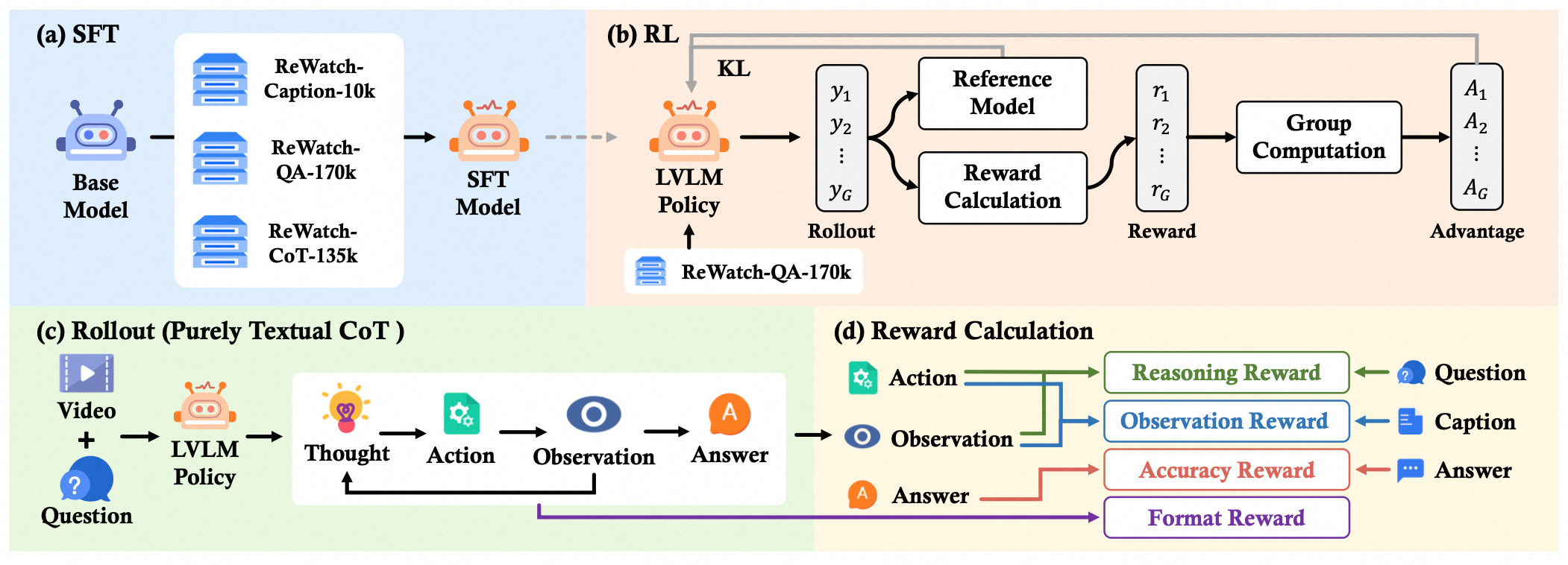
(a) A Base Model is first fine-tuned (SFT) on all ReWatch datasets, (b) then further refined as a policy via Reinforcement Learning (RL) using the ReWatch-QA dataset. (c) The "Rollout" panel illustrates the generative process of the policy: producing a purely textual chain-of-thought that simulates a Thought-Action-Observation reasoning loop through self-generated text segments. (d) We employ four verifiable reward mechanisms.
Results
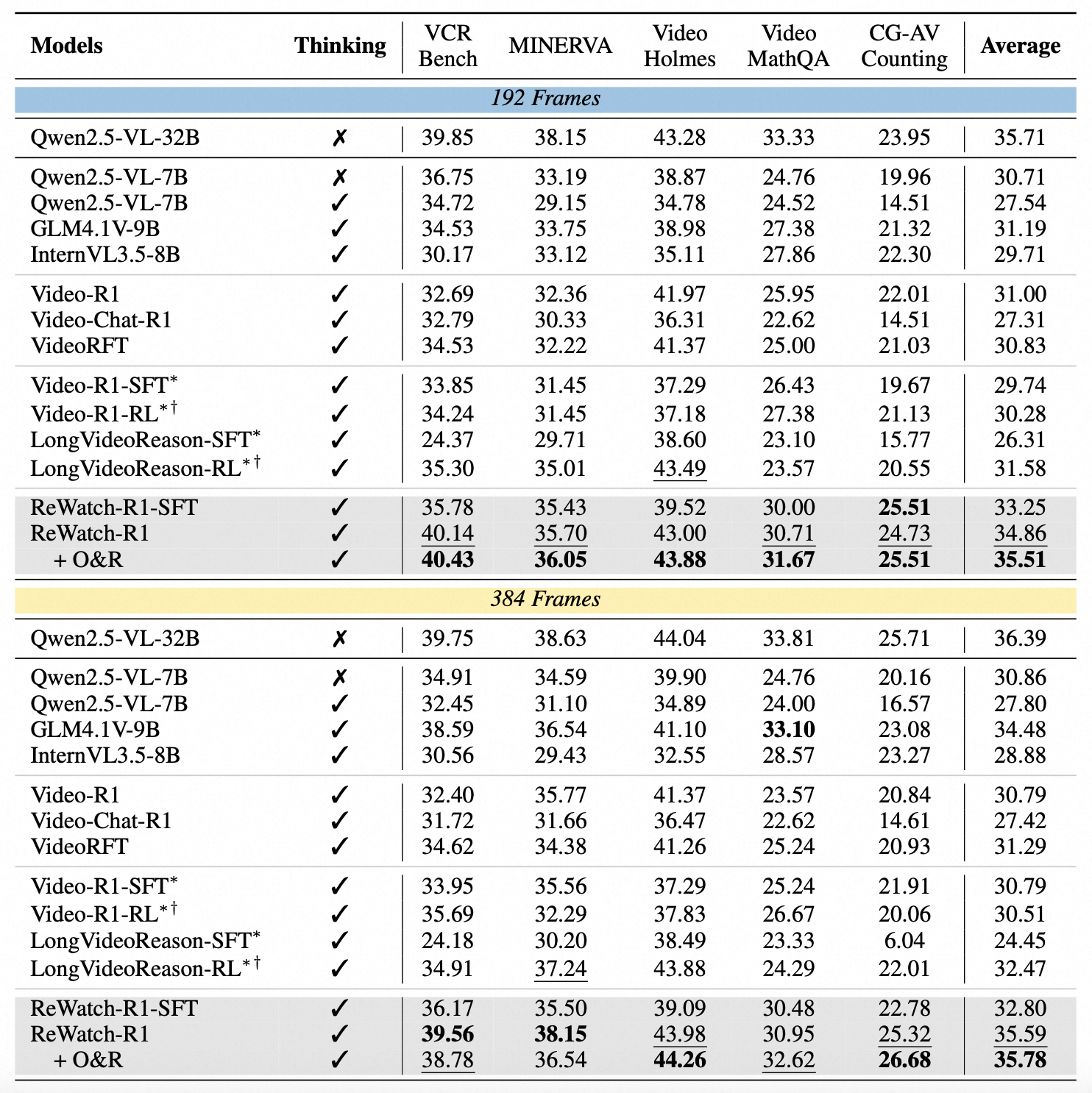
Performance comparison on Video Reasoning tasks. * indicates that we reproduced the model using a training configuration with 192 frames. † indicates that reinforcement learning is conducted using exactly the same data as ReWatch-R1.
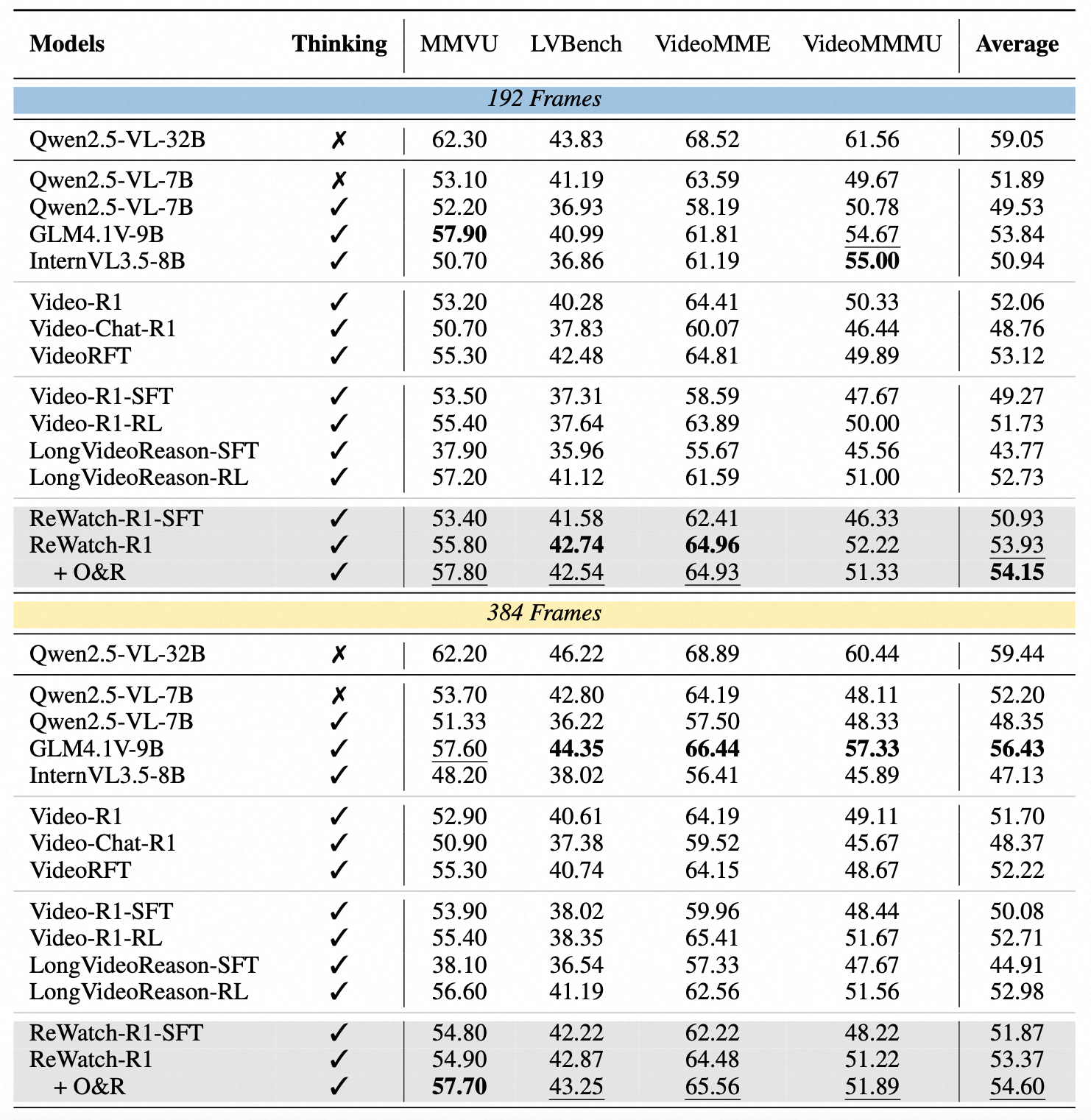
Performance comparison on Video Understanding tasks. * indicates that we reproduced the model using a training configuration with 192 frames. † indicates that reinforcement learning is conducted using exactly the same data as ReWatch-R1.
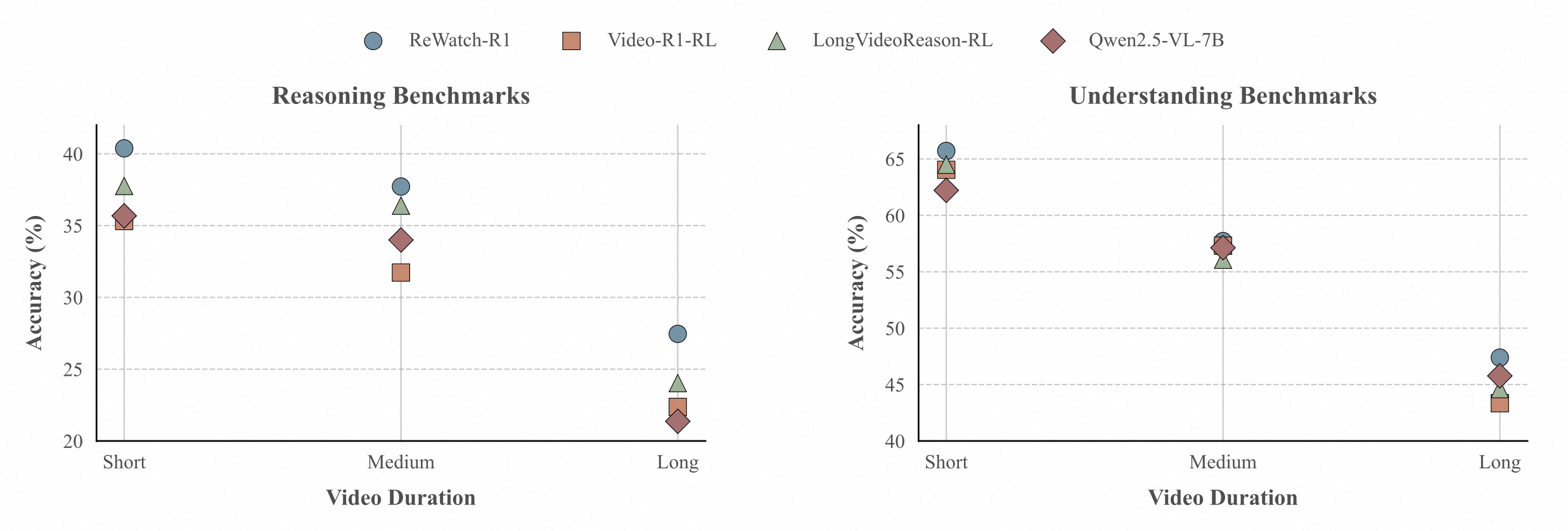
Performance comparison across different video durations. Short: 0-3 minutes, Medium: 3-20 minutes, Long: over 20 minutes. We averaged the performance of the benchmarks for reasoning and understanding respectively, and all results were evaluated at 192 frames.
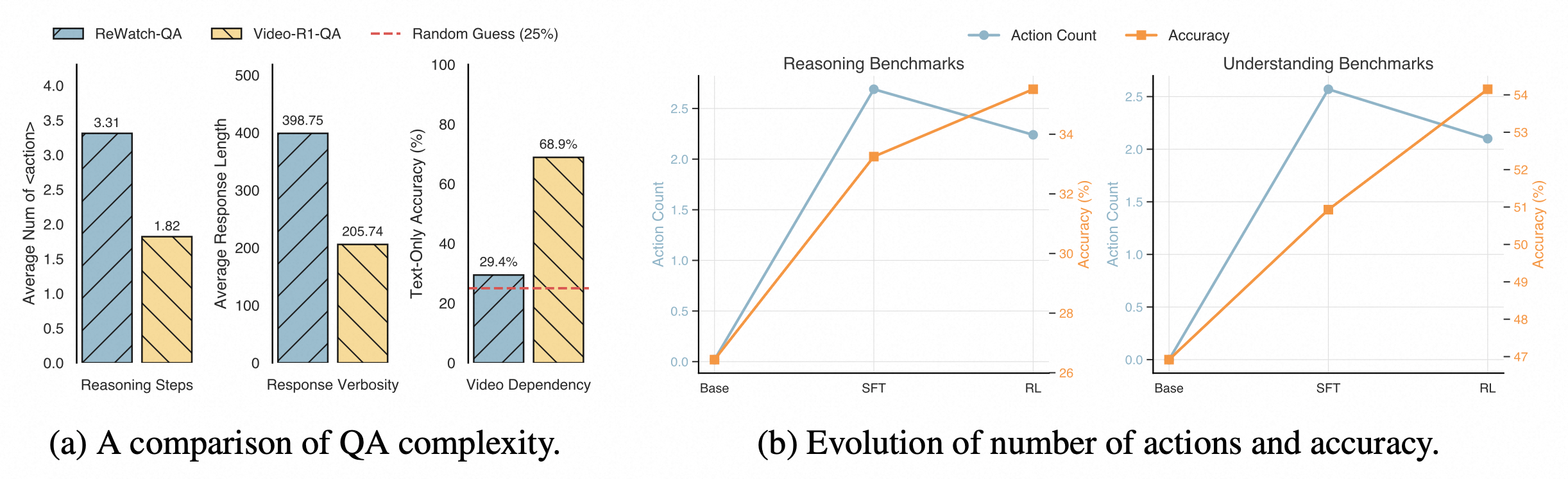
Analysis on QA complexity and Evolution of action count.
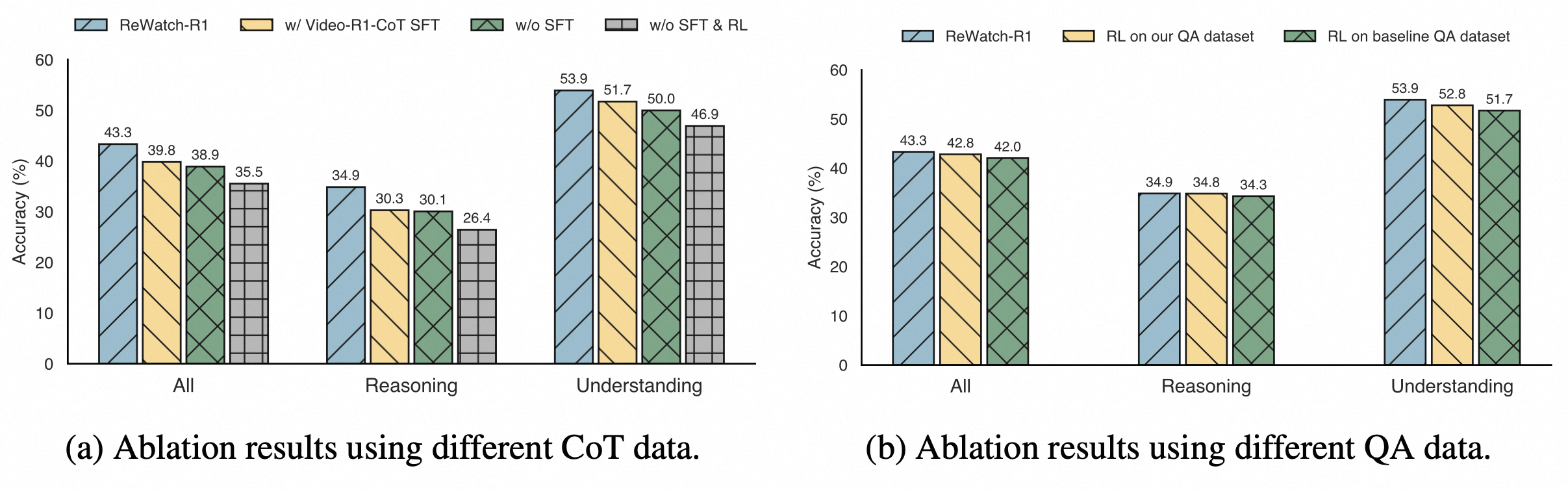
Ablation results of our synthesized data against baselines.
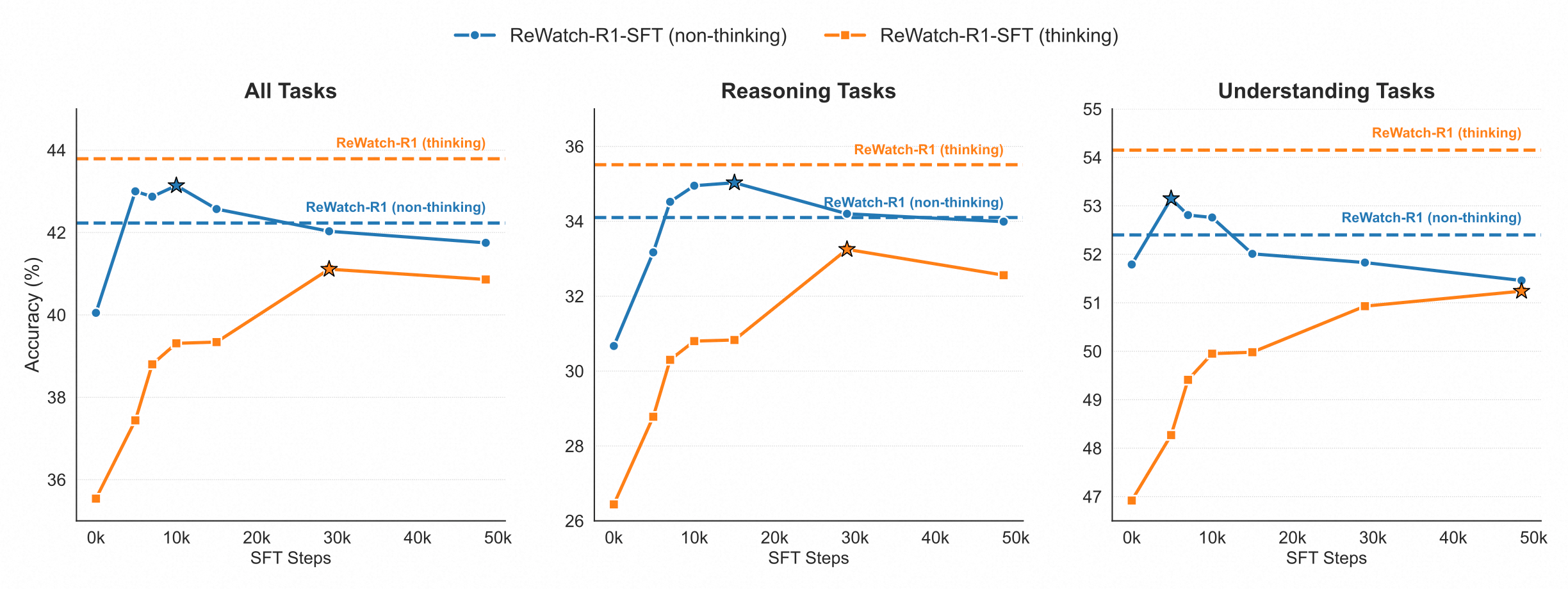
Impact of SFT and RL on different prompting methods. The plots show the accuracy of our ReWatch-R1 model with "thinking" (ReAct) vs. "non-thinking" (direct answering) prompting. Solid lines show performance progression during the SFT phase, dashed lines show the final performance after RL.
BibTeX
@misc{zhang2025rewatchr1boostingcomplexvideo,
title={ReWatch-R1: Boosting Complex Video Reasoning in Large Vision-Language Models through Agentic Data Synthesis},
author={Congzhi Zhang and Zhibin Wang and Yinchao Ma and Jiawei Peng and Yihan Wang and Qiang Zhou and Jun Song and Bo Zheng},
year={2025},
eprint={2509.23652},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2509.23652},
}